Index란?
Index를 사전에 검색을 해보면 '색인' 이라고 나옵니다. 색인이라고 하면 조금 어렵게 느껴질 수 있는데 쉽게 말해서 목차라고 생각하면 편합니다. 예를 들어보겠습니다.
500 페이지가 넘는 책에서 원하는 정보를 찾는다고 생각해 봅시다. 목차가 없는 경우 한 페이지씩 넘겨보면서 원하는 정보를 찾아야 합니다. 운이 좋으면 10 페이지에서 찾을 수 있고 운이 안 좋으면 490 페이지에서 찾을 수 있습니다. 만약에 목차가 있다면 어떻게 찾을 수 있을 까요?? 앞에 목차를 보고 원하는 챕터를 펼쳐서 찾을 수 있습니다. 그러면 좀 더 빠르게 찾을 수 있겠죠
index가 바로 위와 같은 역할을 합니다. 데이터베이스에서 데이터를 찾을 때 모든 데이터를 다 훑어보는 것이 아니라 원하는 데이터들만 쏙쏙 뽑을 수 있게 해줍니다. 즉, 데이터베이스에서 테이블에 대한 검색 속도를 향상시켜주는 자료구조입니다.
Index 종류
앞에서 index에 대해서 간략하게 얘기를 해보았습니다. 이제 Index의 종류를 알아보고 하나씩 간략하게 얘기를 해보려고 합니다. 크게 index 종류에는 B-tree index, B+tree index, Hash index가 있습니다. B-tree, B+tree index의 경우 Mysql에서 기본으로 사용되는 index입니다. 한 번 확인을 해보겠습니다.
Mysql에서 Index를 확인하는 명령어는 다음과 같습니다.
show index from <table_name>위의 명령어를 mysql에 입력하면 다음과 같이 나옵니다.

여기에 index_type을 보면 'BTREE'라고 적혀있는 것을 볼 수 있습니다. 찾아보면 Mysql은 B-tree, B+tree를 전부 사용한다고 합니다. 물론 다른 index도 사용한다고 합니다.
그럼 B-tree부터 하나씩 살펴보겠습니다.
B-tree
B-tree의 구조는 다음과 같이 생겼습니다. Binary tree 구조와 비슷하게 생겼지만 더 많은 child node를 갖을 수 있습니다. 또한 한쪽에 node가 쏠려있지 않고 균형이 잡힌 balanced tree구조입니다.
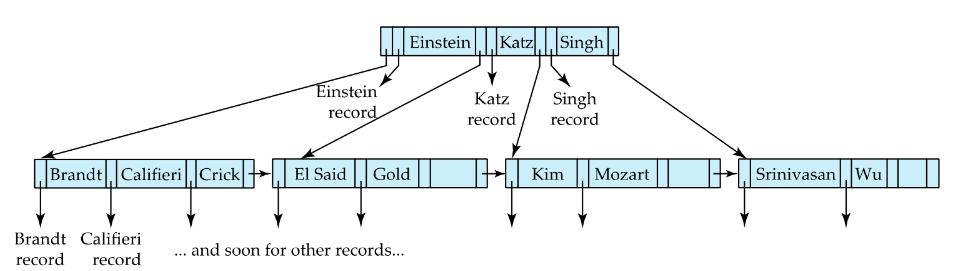
- 내부 및 internal node에 key와 data모두 저장할 수 있다
- 검색이 leaf node가 아닌 곳에서 끝날 수도 있다. -> O(1)만에 검색이 가능할 수도 있다.
- Index keyword가 tree를 통틀어 총 한 node에만 나타납니다.
B+tree
B+tree의 구조는 다음과 같습니다. B-tree와 비슷하게 생겼습니다. B-tree와 B+tree는 binary가 아니라 balanced를 뜻합니다. 가장 큰 특징으로는 리프 노드가 모든 데이터를 저장하고 서로 연결되어 있다는 점입니다.
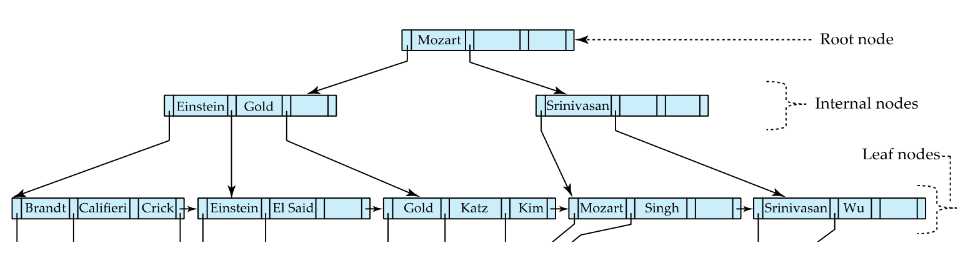
- 평균적으로 탐색 속도가 O(logN)이다.
- leaf node에 데이터가 저장되어 있고 leaf node끼리 연결이 되어 있으므로 전체 탐색이나 range query에 적합하다
- leaf node를 제외하고 데이터를 저장하지 않기에 저장공간을 비교적 적게 차지 한다. -> 더 큰 범위를 인덱싱할 수 있다.
B-Tree vs B+Tree
B-Tree와 B+Tree를 보면 비슷하게 생겼습니다. 어떤 차이점이 있는지 얘기해보겠습니다.
- B+Tree는 leaf node에 data가 존재하기 때문에 평균적으로 query time이 logN으로 고정되어 있습니다. 이에 반해 B-tree의 경우 leaf node말고 다른 node들도 데이터를 갖고 있습니다. 그래서 query time이 고정적이지 않고 최적일 때는 O(1)의 시간이 걸립니다.
- B+tree의 경우 leaf node에 데이터가 있고 leaf끼리 연결이 되어있기에, 전체 탐색을 하거나 range query에 적합합니다. B-tree의 경우 전체 탐색을 하기 위에 모든 node를 방문해야 합니다.
- B+tree의 경우 leaf node를 제외하고 데이터를 저장하지 않기에 더 크고 정확한 범위를 인덱싱할 수 있습니다.
Hash
Hash index는 hash function을 이용하여 데이터를 저장하는 방식입니다. 아래 그림을 보면 hash function을 이용하여 해당하는 bucket에다가 데이터를 저장하는 방식입니다. 여기서 bucket은 다른 특별한 공간이 아니라 disk block이라고 생각하면 됩니다. 쉽게 말해 특별한 규칙(hash)을 사용하여 데이터를 해당 disk block(bucket)에 저장하는 방식입니다. Hash의 종류에는 여러가지 종류가 있습니다.
크게 Static Hashing과 Dynamic hashing이 있습니다. 자세하게 다루지는 않고 간단하게 말해보겠습니다. Static hashing은 bucket의 숫자가 고정되어 있는 방법입니다. 이 방법으로 충분히 데이터를 저장할 수 있지만 bucket의 용량이 없거나 record(data)가 한 bucket에만 쏠려서 bucket overflow가 일어날 때 bucket의 수를 늘려주어야 합니다. 해결할 수 있는 방법이 2가지가 있는데 한 가지 방법은 Rehashing을 하는 방법이고 두 번째 방법은 bucket의 수를 동적으로 변경시키는 방법입니다. 여기서 동적으로 변경시키는 방법을 영어로 dynamic hashing이라고 부릅니다. dynamic hashing의 종류와 자세한 설명은 구글에 검색하면 자세하게 설명해 주는 블로그들이 많습니다.

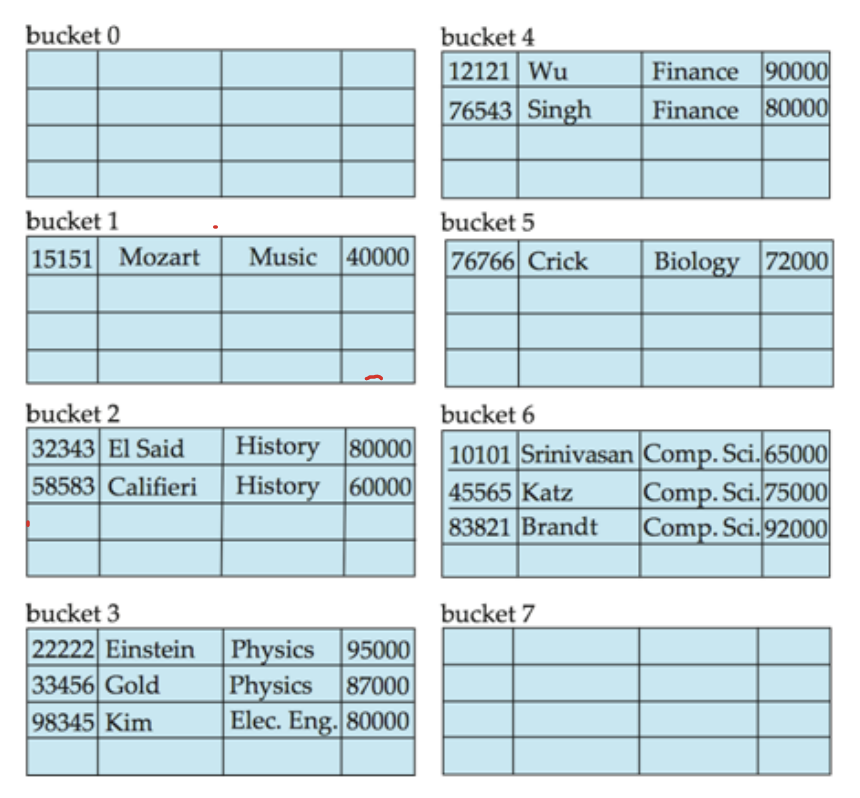
- 전반적인 검색을 하지 않고 hash만 하면 되기에 query time이 빠릅니다.
- 동등 비교(=)검색 시 사용 및 최적화 되어 있다.
Hash vs BTree
- Hash는 B-Tree나 B+Tree처럼 root node부터 찾는것이 아니라 특정한 해시 알고리즘으로 즉시 찾을 수 있기에 빠르다
- range query의 경우 Hash는 전부 다 조회를 해야하기에 느리다. -> 원래 순서 키 값이 해시 알고리즘 이후에 불연속적으로 될 수 있기에
- 확장성 면을 봤을 때, BTree index의 경우 당연히 index insert하는 경우 시간적 비용이 듭니다. 하지만, 해시의 경우 static hashing을 할 때 rehashing을 하면 큰 overhead 가 발생하고 dynamic hashing을 사용할 경우도 일반적으로 overhead가 더 큽니다.
위에서 index의 역할과 종류에 대하여 알아보았습니다. Index를 사용하면 우리가 원하는 데이터를 엄청 빠르게 찾을 수 있습니다. 그렇다면 모든 Column에 index를 걸어서 조회를 빠르게 하는 방법은 어떤가요?
모든 Column에 Index를 만드는 것이 좋을까??
모든 것에는 trade-off가 있습니다. Index도 마찬가지입니다. 모든 column을 index할 수 는 있지만 그렇게 하지 않습니다. Indexing을 하면 다음과 같은 추가적인 비용이 발생합니다.
- index 저장을 위한 추가적인 storage가 필요합니다.
- create(생성), update(변경), delete(삭제) 할 때 index도 update 되어야 합니다.
앞서 예를 들었던 책을 생각해보면됩니다. 책에서 원하는 것을 빨리 찾기 위해 책 앞에는 목차가 존재합니다. 모든 페이지에 대한 목차를 만들면 목차 페이지도 늘어나고 원하는 목차를 찾는데도 시간이 오래걸립니다. 데이터베이스도 마찬가지로 index를 저장하기 위한 추가적인 저장공간이 필요합니다. 또한 책에 내용을 추가할 때 목차를 수정해주어야 하고 내용을 뺄 때 목차에서도 해당 목차 부분을 제거해주어야 합니다. Index도 마찬가지로 데이터가 생성, 변경, 삭제 될 때 update를 해줘야 합니다.
따라서 모든 Column에 Index를 만들기 보다는 꼭 필요한 column에 index를 설정해주어야 합니다. 불필요한 index또한 저장공간을 잡아먹고 성능을 느리게 합니다.
그러면 어떤 경우에 Index를 사용해야 하고 어떤 경우에는 Index를 사용하면 안될까요??
Index를 사용하면 안되는 경우
Index를 사용하면 안되는 경우는 크게 3가지가 있습니다.
- 데이터 조회보다 쓰기가 더 빈번하게 일어나는 table의 경우
- Cardinality가 낮은 경우
- 작고 고정된 테이블의 경우
첫 번째 경우는 조회보다 쓰기가 빈번하게 일어나는 table의 경우입니다. Index의 역할을 생각해보면 책의 목차와 같은 역할을 하며 원하는 데이터를 조회할 때 성능을 향상시켜 줍니다. 하지만 table에 조회는 안하고 쓰기만 일어날 경우, 쓰기를 할 때 index를 생성함으로 시간적 비용이 들고 조회를 하지 않기에 index의 유용성이 떨어집니다.
두 번째 경우는 Cardinality가 낮은 경우입니다. Cardinality란 쉽게 말해서 데이터의 중복정도를 나타내는 수치라고 보면 됩니다. 데이터의 중복이 많으면 cardinality가 낮고, 데이터의 중복이 없으면 cardinality가 높습니다. 그러면 왜 cardinality가 낮으면 index를 사용하면 안되는 것일까요?? 예를 들어 총 100개의 학생 데이터가 있습니다. 성별을 나타내는 column이 있다고 가정해 봅시다. 95개의 데이터가 남자이고 5개의 데이터는 여자입니다. 이 때 성별을 나타내는 column은 cardinality가 낮습니다. 이럴 경우 성별을 나타내는 column보다는 더 높은 cardinality가 있는 column에 index를 생성해주는 것이 좋습니다.
세 번째의 경우는 작고 고정된 테이블일 때 입니다. 예를 들어 베스킨라빈스 31 아이스크림 데이터를 갖고 있는 테이블이 있다고 해봅시다. 베스킨라빈스 31이름처럼 테이블에는 데이터가 31개만 존재합니다. 또한 삭제되고 추가되는 데이터가 없습니다. 이럴 경우 index를 이용하여 탐색을 할 경우와 index 없이 전체 탐색을 하는 경우에 차이가 미미합니다.
※ 공부하면서 정리한 내용이므로 잘못된 내용은 언제든지 지적 부탁드립니다.
참고자료
https://stackoverflow.com/questions/7306316/b-tree-vs-hash-table
B-Tree vs Hash Table
In MySQL, an index type is a b-tree, and access an element in a b-tree is in logarithmic amortized time O(log(n)). On the other hand, accessing an element in a hash table is in O(1). Why is a hash
stackoverflow.com
https://dev.mysql.com/doc/refman/8.0/en/index-btree-hash.html
MySQL :: MySQL 8.0 Reference Manual :: 8.3.9 Comparison of B-Tree and Hash Indexes
8.3.9 Comparison of B-Tree and Hash Indexes Understanding the B-tree and hash data structures can help predict how different queries perform on different storage engines that use these data structures in their indexes, particularly for the MEMORY storage
dev.mysql.com
What is the difference between Mysql InnoDB B+ tree index and hash index?
The most important difference between B-tree and B+ tree is that B+ tree only has leaf nodes to store data, and other nodes are used for…
medium.com
https://codingsight.com/hash-index-understanding-hash-indexes
'CS' 카테고리의 다른 글
| [NETWORK] ARP란? (0) | 2023.05.13 |
|---|---|
| [Database] SQL vs NoSQL (0) | 2021.12.07 |
| [Linux] Linux File Hierarchy Structure (0) | 2021.09.08 |