배경
우연히 영화 무대인사를 보러 가게되었는데, 너무 너무 재밌었다. 😄 그 후에도 기회가 될 때 보러 가려고 하였는데, 인기 있는 무대 인사의 경우 자리가 없어 예매를 못하게 되었다.... 어떻게 많은 사람들이 무대인사 예약을 빨리 할까하고 찾아보았다.
무대인사나 시사회만 모아줘서 보여주는 사이트도 존재하였고, 지인들에게 물어보니 요새는 SNS에 다 올라오기도 하고 팬 카페에 공지가 되어서 사람들이 빠르게 정보를 접할 수 있다고 하였다. SNS를 하지도 않고, 팬 카페 활동도 안하는 내가 어떻게하면 원하는 영화 무대인사를 갈 수 있을까 고민을 하다가 영화 무대인사 정보를 자동으로 알려주는 서비스를 만들어 보자고 생각을 했다.
개발한 code의 경우 github에서 확인할 수 있다.
https://github.com/Rabongg/movie_preview
GitHub - Rabongg/movie_preview
Contribute to Rabongg/movie_preview development by creating an account on GitHub.
github.com
Version 0(Beta)
v0의 경우 빠르게 기능을 개발하는 것에만 초점을 맞추어서 개발을 하였다.
사용 기술
- Python 3.11
- Mysql 8.x
기능
version 0의 경우 python으로 개발을 하였다. Python을 선택한 이유는 여러가지가 있었는데, 빠르게 개발을 하고 싶었고, 웹 크롤링 기능을 사용하기에 선택하였다.
기능을 간단하게 도식화 하면 다음과 같다.
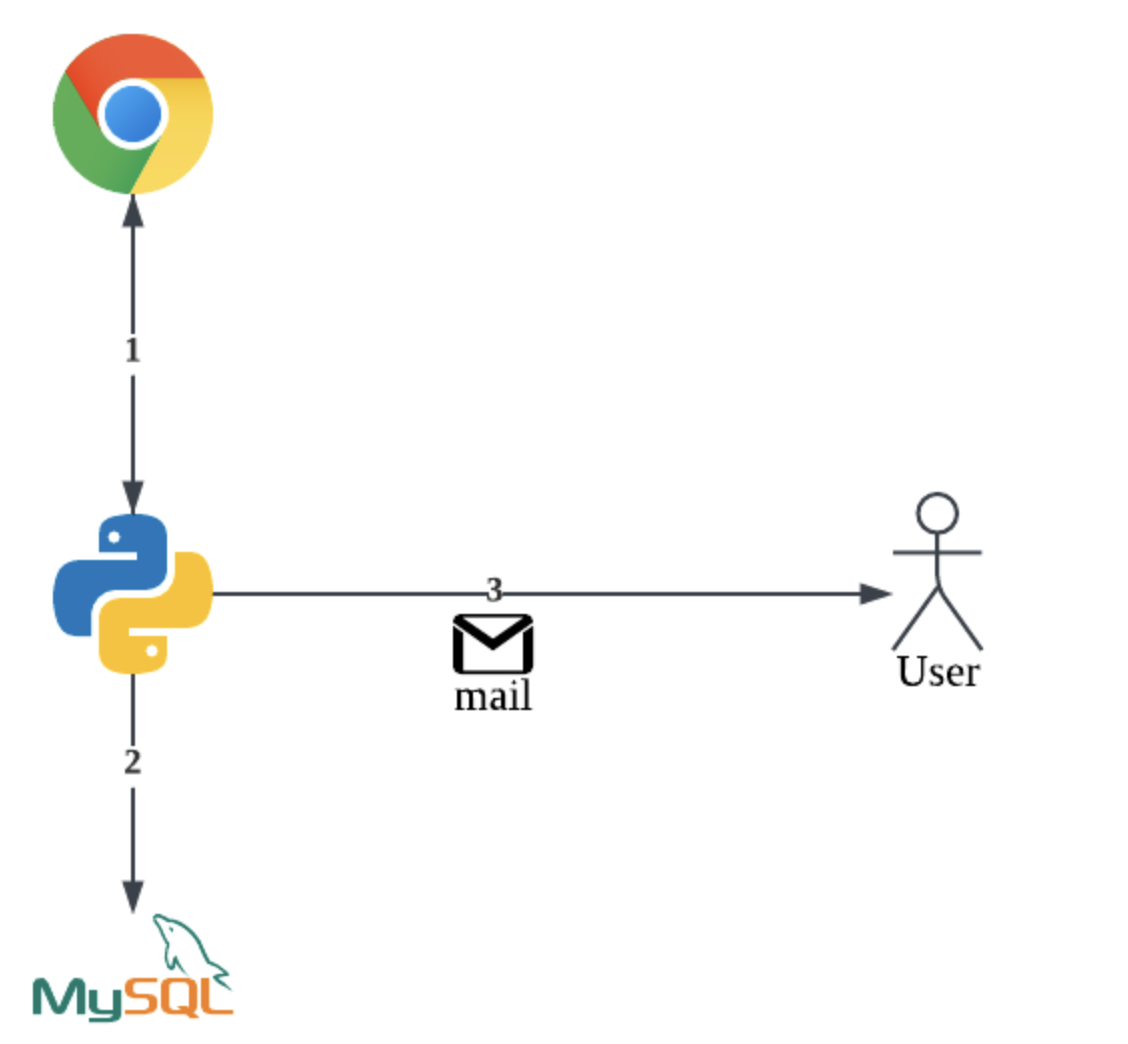
- Python을 이용하여 웹 크롤링을 진행한다.
- 디비에 데이터를 저장하였다.
- 사용자에게 메일 전송
좀 더 자세하게 얘기하자면, Python을 이용하여 웹 크롤링을 진행하였다. 웹 크롤링을 한 사이트는 대중적인 영화 사이트인 CGV, LOTTE, MEGABOX 3개의 사이트에서 무대인사 부분의 데이터를 갖고왔다.
데이터를 갖고 온 후에, 가공하여 데이터베이스에 저장하였다. 매번 같은 데이터가 아닌, DB에 없는 데이터인지 비교 후에 없는 데이터들만 저장을 하였고, 새로운 데이터들만 사용자에게 메일로 보내였다.
사용자에게 알림을 보내는 기능을 개발할 때 어떤 알림을 이용하는게 가장 적합한지 고민을 하게 되었다.
당연히, 문자(SMS)나 메신져(카카오톡)가 편하고 확인하기 수월하다. 그러나 해당 기능의 경우 발송 건당 추가적으로 돈이 들어가서 1인 서비스로 사용하기에는 과하다는 생각이 들었다. 푸시 알림의 경우 웹 서비스나 모바일 앱이 있어야 가능했기에, 배보다 배꼽이 더 큰 것 같아서 사용하지 않았다. 그러하여, 이메일 서비스를 이용하여 사용자에게 알림을 보내기로 결정하였다.
후기
결론을 말하자면, 해당 서비스를 이용해서 원하는 영화 무대인사를 여러 번 다녀올 수 있었다. 😀😀
서비스 자체도 혼자 사용하고자 만들었기에 문제가 없었다. 그러면서도, 코드를 좀 더 깔끔하게 리팩토링하고 싶은 욕심도 생기게 되었다. 무엇보다, 해당 서비스의 완벽한 자동화를 꿈꾸게 되었다.
현재 내가 개발한 서비스의 경우, 새로운 정보가 없으면 이메일을 안 보내는 구조이다. 데이터가 실제로 없어서 안 보내는지, 아니면 서비스에 에러가 생겨서 안 보내는지에 대해 알 수 가 없었다... 매일 로그를 직접 보면 확인이 가능하지만, 신경을 안써도 자동으로 동작하는 서비스를 원했기에 서비스를 리팩토링 하기로 결정하였다.
Version 2
v2의 경우 v0와 다르게 빠르게 기능만 구현하려고 하지 않았고, 유지보수성이나 확장성 등에도 초점을 맞추어서 개발을 진행하였다.
사용 기술
- Python 3.11
- Mysql 8.x
- Redis 7.4
- Java 17이상
- spring boot 3.4.x
기능
version 2의 경우 version 0과 다르게 Python으로만 개발하지 않았다. 분리한 이유는 크게 3가지가 있다.
첫 번째는 역할을 분리하여 유지보수 및 확장성을 용이하게 하고 싶었다. version 0에서는 Python 프로그램이 전부 담당하고 있어서 만약 확장을 하려고 해도 해당 process 전부를 여러 개 띄워야 한다. 분리를 하면, 웹 크롤링만 확장하고 싶으면 Python 의 프로세스만 여러 개 띄워서 처리할 수 있다. 또한, 역할을 분리함으로써 유지보수도 쉬워진다. 추후 에러 발생에 대한 alert가 왔을 때, 어떤 기능에서 에러가 발생했는지 확인이 빠르게 가능하다.
두 번째는, Spring boot를 사용하면 데이터 관리에 용이성이 있다. Python에서도 sqlalchemy 등 라이브러리를 사용하여 트랜잭션을 지원하게 할 수 있다. 하지만 Spring boot에서는 JPA의 트랜잭션 관리 기능을 내장하고 있어서 따로 개발자가 신경 쓸 일이 거의 없다.
세 번째로 pub/sub 기능을 사용하고 싶었다. 비즈니스 서비스가 아니라, 개인적인 프로젝트라서 pub/sub 기능을 사용하고 싶기도 했다. Python, Spring boot로 분리를 하는 순간, 2개의 서비스 사이에서 데이터를 주고 받기 위해 pub/sub 구조를 사용해야하기에 분리한 이유도 있다.
기능을 간단하게 도식화 하면 다음과 같다.
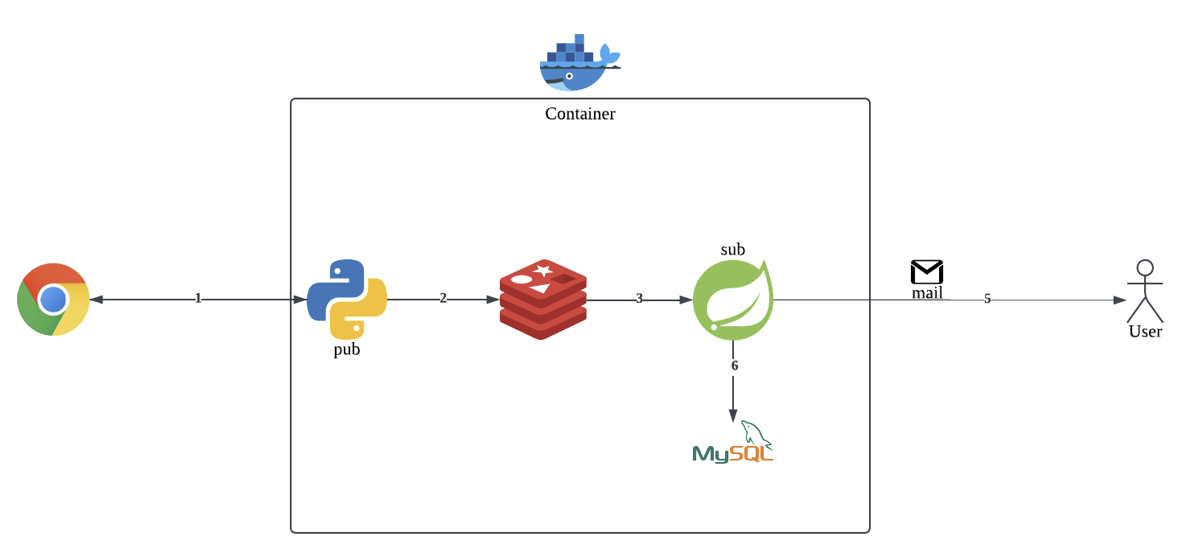
- Python을 이용하여 웹 크롤링을 진행
- 데이터를 가공하여 Redis로 전달(publish)
- Redis Pub/Sub 구조에서 Spring으로 데이터를 전송
- Spring에서 사용자에게 메일을 전송
- 전송한 데이터를 데이터베이스에 저장
각 단계를 자세히 설명해보겠다. 첫 번째로 Python에서 웹 크롤링(cron 매일 오전 9시, 오후 4시)을 진행한다. 웹 크롤링 진행 후, 데이터만 가공해서 Redis로 데이터를 보낸다. Redis에서 해당 데이터를 받고 Spring boot로 데이터를 보낸다. 데이터를 받은 Spring 서비스에서는 DB에 존재하는 데이터인지 확인을 하고, 새로운 데이터들만 사용자에게 이메일로 전송한다. 전송이 성공적으로 되었으면, 데이터를 DB에 저장을한다.
v2 버전을 개발하면서, 고민했던 부분들이나 겪었던 어려웠던 사항에 대해서는 아래에서 좀 더 자세하게 적어보겠다.
Pub/Sub 구조
Pub/Sub 구조를 지원하는 시스템에는 크게 Redis, Kafka, RabbitMQ 등이 있다.
이 중에서 Redis를 사용하였는데, 다른 시스템과 비교하였을 때 간단하고 빨라서 사용하였다. 발행한 메세지를 따로 저장하지 않는다는 단점이 있지만, 해당 서비스에서 발행한 메세지의 정확한 전달 보장(?)이 크게 중요하지 않았다. Python 프로그램이 매일 오전 9시, 오후 4시마다 데이터를 갖고 오기에, 오전 9시의 데이터가 유실되도 오후 4시에 포함되기 때문에 유실되도 문제가 없었다. 또한 영화 데이터이고 민감한 데이터가 아니였다.
또한 실시간으로 웹 크롤링 된 데이터를 전달하고 받기만 하면 되어서 적합하였다. 메세지 순서 보장도 필요가 없었다.
Redis의 경우, 현재 사용자가 많지 않기에, 단일 구조로 배포를 해둔 상태이다. 데이터도 매일 딱 2번 정도만 받기에, 굳이 cluster나 sentinel을 사용하지 않아도 된다고 생각하였다. (추후, 해야한다면 변경할 예정이다)
이메일 화면
알림의 경우 v2에서도 v0와 마찬가지로, 이메일 알림을 사용하였다. v0 버전은 빠르게 만들기 위해 이메일 디자인에도 신경을 안쓰고 정보 전달에 초점을 맞췄다. 다른 사람이 보면, 이게 뭐지 할 정도긴하다....
v2에서는 이메일도 사용자가 봤을 때 한 눈에 알아볼 수 있게 수정하였다. 정보를 받아보고 싶다고 하는 사람이 생겨서... 이쁘게 만들기도 하였다.
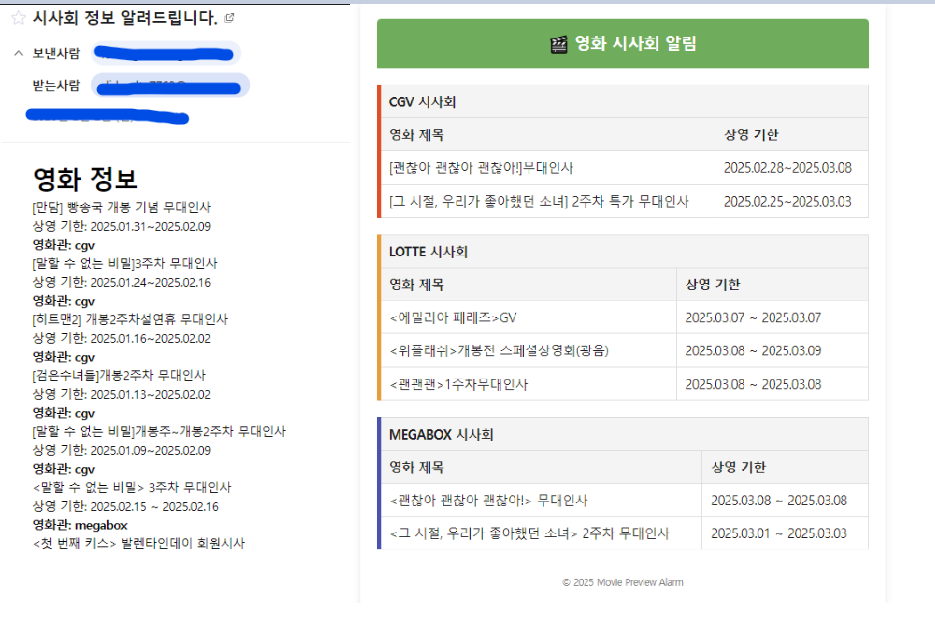
이메일 전송을 하고나서, 특이한 점 몇가지가 있었다. 이메일마다 지원하는 코드(?)가 조금씩 달랐다.
크게 2가지가 있었는데, style tag와 < > 이었다.
style tag의 경우 gmail에서는 정상적으로 동작을 하였는데, naver 메일에서는 정상적으로 동작을 하지 않았다. 원하는 대로 동작 시키기 위해 <style> </style> 태그 대신 각 tag안에 inline style 형식으로 스타일을 추가를 해줘야 했다.
< >의 경우, 위의 사진에서 보이다시피 제목에 해당 기호가 포함되어 있는 경우가 있다. naver 메일 에서는 상관이 없었지만, gmail에서는 tag로 인식하여 제목이 안나오는 경우가 발생하였다. 이 경우에는 <는 `<`, >는 `>`로 변환해주는 StringEscapeUtils를 지원해주는 자바 라이브러리를 사용하였다.
배포 환경
v0의 경우 배포를 window 로컬 컴퓨터에 하였는데, v2는 우분투 서버(aws, gcp 등)에 배포를 하려고 하였다. 서버에 코드 전체를 옮기고 배포할 수도 있지만, docker를 사용하면 수월하기에 docker를 사용하여 배포를 하였다.
docker 컨테이너 내부에서 웹 크롤링을 하려면 브라우저가 필요했다. 정적 페이지를 크롤링할 때는 requests를 이용하여 조회 후에 데이터를 가공하면 되었지만, 영화 시사회 사이트의 경우 동적 데이터가 있어서 브라우저를 이용하여 크롤링을 해야했다. 로컬에서 프로그램을 돌렸을 때는 chrome이 기본적으로 설치가 되어 있어서, 상관이 없었지만, docker container 내부에는 직접 설치를 해야했다.
당연히, 각 서비스 코드에서도 각 container와 통신하기 위해, DB나 redis 설정하는 부분을 수정해야했다. localhost가 아닌 container 이름으로 전부 수정해야했고, volume도 mount를 해야 컨테이너가 죽었을 때 데이터가 날아가지 않기에 설정도 해주었다. docker 설정의 경우도 위의 github의 docker-compose.yaml로 확인할 수 있다.
로그
v2 기능 개발을 할 때 제일 신경 쓴 부분이 로그였다. 애초에 v0에서 v2로 리팩토링한 이유도 에러 발생 시 grafana에서 이메일로 알림을 줄 수 있게 완벽한 자동화를 만들기 위함이였다. 고로, log를 잘 남겨야 grafana에서도 의미있는 알림을 줄 수 있을 것이라고 생각했다.
흔히들 잘 아는 log level을 기준으로, info 및 error 로그를 남겼다. 보통, 다른 API 호출이나 자신의 서비스의 에러가 아닐 때 warn level로 로그를 설정한다고 많이들 한다. 그러나 해당 서비스의 경우 실시간 성 알림이 중요하기에, 다른 API 호출 실패일 때도 빠르게 수정을 해야해서, error 레벨로 설정하였다.
로그 수집과 알림 에 대한 이야기는 다음 블로그에 자세히 적을 예정이다.
후기
리팩토링 후에도 여전히 무대인사나 시사회 관련 알림은 잘 오고 있다!!!
사실 에러가 발생할 확률이 거의 없긴한데, 알림 덕분에 크롤링하는 URL이 변경이 되었거나 하는 정보들을 빠르게 알 수 있었다. 또한, 사용 안해봤던 pub/sub나 loki, grafana 등을 사용할 수 있었다.
일상에서 필요성에 의해서 만든 프로젝트라서 개발하는 내내 재밌었다. 현재는 해당 서비스를 만족하면서 사용하고 있다. 추가적으로 기능이 필요하다고 생각이 되거나, 재밌겠다고 생각이 들면 그 때 좀 더 서비스를 발전시키려고 한다.
'프로젝트' 카테고리의 다른 글
| Promtail + loki + grafana를 이용한 로그 구축 (0) | 2025.03.17 |
|---|